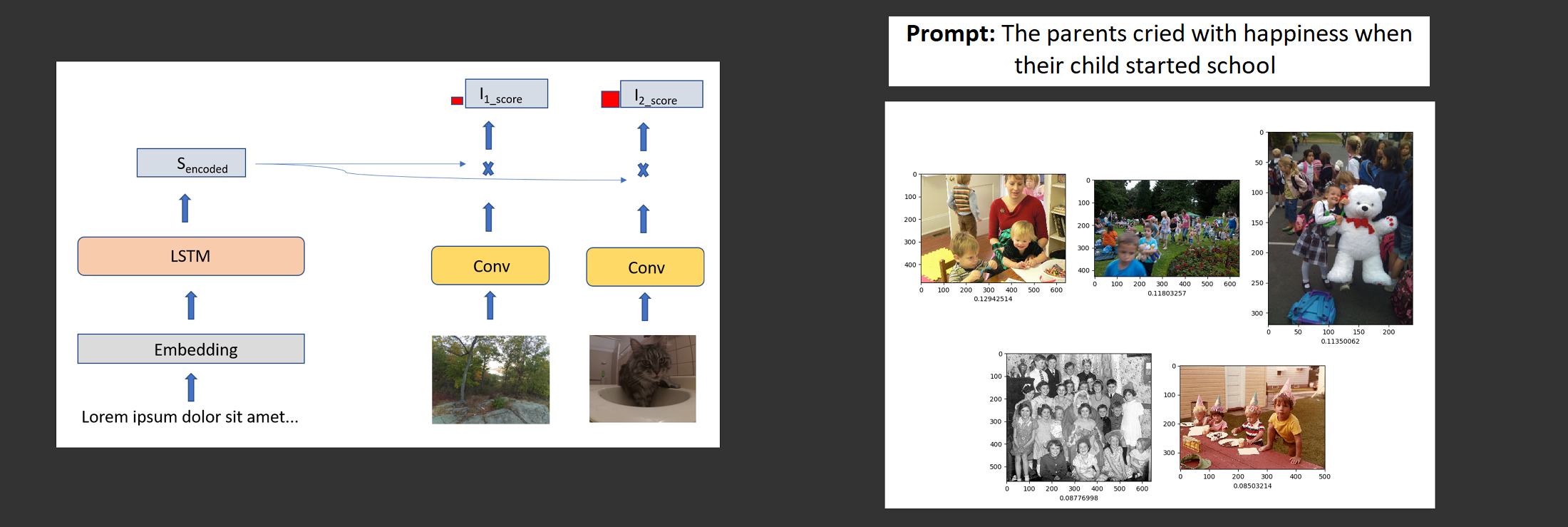

Deep Network to Compute Image-Text Similarity to Help Image Selection
To help writers select a image from a large image database to help represents a prompt, using PyTorch we designed a network to compute the similarity between the text prompt and the images. We used a LSTM for the text, a ImageNet/DenseNet for the image, and the cosine similarity to compute their similarity at their final layer. We find promising results as seen in the header image.
This was a class project for CS6740: Advanced Language Technologies, spring of 2018 at Cornell University taught by Claire Cardie.
Methods
- Technology: We wrote the code in Python using PyTorch. I wrote the DenseNet and training/inference code.
- Dataset: Coco 2017 dataset, that contains many images and 5 captions per image.
- Network architecture:
- LSTM: We encoded the text using the GloVe embedding and passed it to a LSTM that outputs a vector.
- DenseNet: We encode the image using a DenseNet trained on ImageNet that outputs a vector.
- Cosine similarity: We compute the cosine similarity between the output vectors of the image and text.
- Inference: Using the cosine similarity, we pick the image with the closest similarity to the text vector.
- Results: As can be seen in the header, the images selected for prompts were related to the prompt, although there’s still much room for improvement.
Abstract
In this paper we explore the task of scoring the fit of an image to a caption. This task has many applications, particularly image search, but is also difficult because it combines two challenging fields in artificial intelligence: natural language understanding and image understanding. We propose a two-part model that uses an image encoder and sentence encoder to encode the image and caption into the same learned embedding space, then compute the cosine similarity between the two vectors to produce a final similarity score. The separate encoders allow for pre-computation of image or caption embeddings as applicable, allowing for very fast inference for applications like image search. We train our model on the 2017 COCO Dataset (Lin et al., 2014) and show promising results in experimentation.