
Maximizing Feature Extraction in DNNs for Transfer Learning
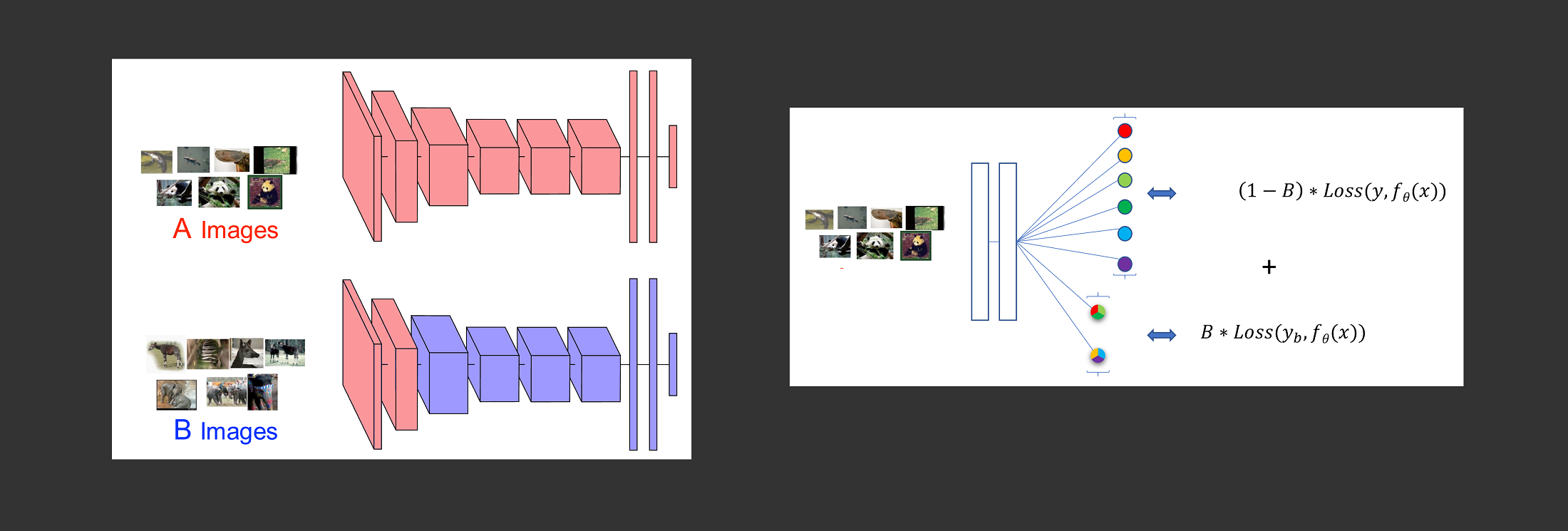
To improve accuracy in transfer learning where a MLP is pre-trained on dataset A such as ImageNet, and then transferred to a new dataset (picture left), using PyTorch we added a new data-driven loss-layer to DenseNet to extract more features on dataset A (picture right). We observed no improvement. We also replicated previous transfer learning results relating freezing-layer depth with performance.
This was a class project for CS6784: Advanced Topics in Machine Learning, fall of 2017 at Cornell University taught by Kilian Weinberger.
Methods
- Technology: I wrote the code in Python using PyTorch.
- Dataset: CIFAR100 dataset that contains 100 image classes (600 images each). We split the dataset for transfer learning.
- Network architecture:
- DenseNet: We used DenseNet to classify the images in the pre-train/transfer datasets.
- Data driven loss: In addition to classification loss, we added a loss layer to classify groups of image classes. See right image in the header and the paper.
- Results: We saw no improvement.
Abstract
Transfer learning enables applying the learning from one dataset on another to improve performance. We replicate previous studies on the relationship between layer depth and feature dataset specificity in AlexNet to DenseNet. We also explored implementing a novel data driven layer that could help extract more features from the first dataset, but we didn’t find a significant improvement.