
Preventing Catastrophic Forgetting in an MLP Online Learning Setting
To prevent “catastrophic forgetting”, where a deep network (MLP) forgets old data as its trained with new data in an online fashion. Using PyTorch we designed a hybrid regression/auto-encoder network, trained it to predict seasonal weather data and found some improvement over a baseline MLP.
This was a class project for CS6787: Advanced Machine Learning Systems, fall of 2018 at Cornell University taught by Chris De Sa.
Methods
- Technology: I wrote the code in Python using PyTorch.
- Dataset: The NOAA hourly weather of weather stations in the US for a whole year.
- Network architecture:
- Baseline: We used a small MLP with a MSE loss to predict the hourly temperature.
- AE: We used an auto encoder, where the output of the encoder is connected to the regression layer predicting temperature, in addition to the decoder layer. The loss was a weighted combination of the AE loss and MSE regression loss.
- Weight constrained: Similar to the baseline, but we added a weight-changing loss to penalize large changes in the network, in addition to the MSE loss.
- Results: We found an improvement in the AE-MLP hybrid network (0.15 vs. 0.19 loss; t-test p value: 0.000027; Cohen’s d: 0.81).
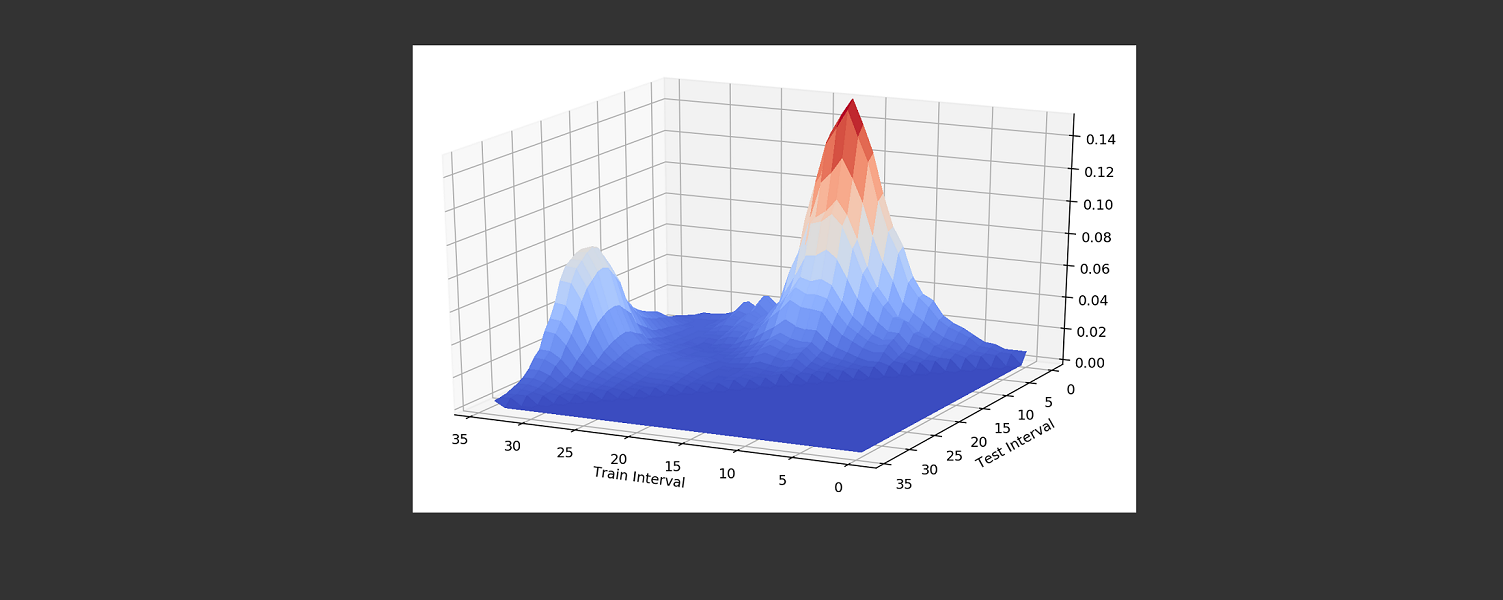
Catastrophic forgetting in seasonal data
The header image shows the test error when training on weather data sequentially. I.e. when training on February data, test error is low for February. But when continuing to train the same network on July data, the test error for February increases, until we continue training on the fall season and then it falls again.
Abstract
Catastrophic forgetting is an undesired phenomenon which prevents a neural network from being used for multiple tasks. We believe that online learning suffers from a similar issue as weights are updated based on most recent data. This can be particularly problematic for data-sets where the time-series data is cyclical in nature, e.g. weather data, and where the cyclic nature of the data is excluded as data feature. Using the NOAA weather data collected from 1981-2010, we first show as a baseline that simply training a multilayer perceptron(MLP) in an online fashion resulted in cyclic spikes in test error. Similar spikes were also observed when the model was re trained with random subsamples of previous data. Finally, we observed that an autoencoder with a novel weighted loss function for an additional regression layer for online learning outperformed the baseline MLP (t-test p value: 0.000027 ; Cohen’s d: 0.81).